$ mkdir planets
$ cd planets
$ git init3. Remote Code Hosting and GitHub
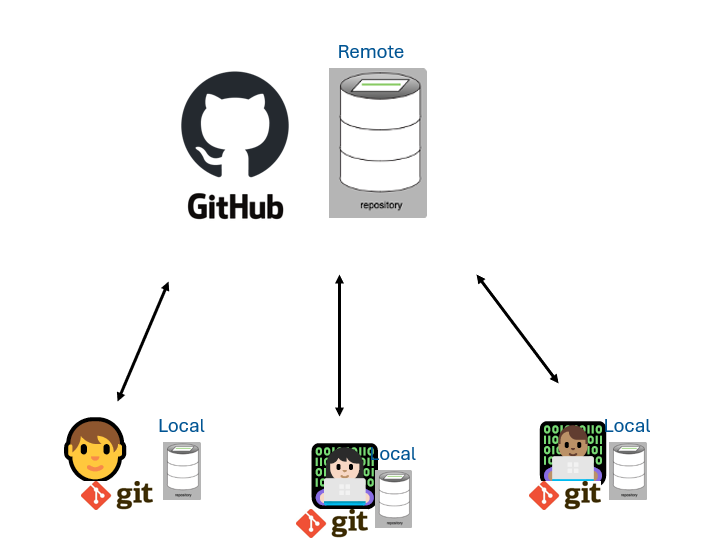
Version control really comes into its own when we begin to collaborate with other people. We already have most of the machinery we need to do this; the only thing missing is to copy changes from one repository to another.
Systems like Git allow us to move work between two or more repositories. The repositories can live on separate computers or network locations. In practice, we often use one copy as a central hub, and keep it on the web rather than on someone’s laptop. This is your source of truth repository. Anything that lives here is what is then shared between collaborators. Each individual collaborating on the project will have a local version of this shared repository on their own computer. This is where you make changes, edits, and updates that you would eventually like to add to the rest of your shared work. Most programmers use a hosting service like GitHub to hold the central repositories; and this is true for many BC Government employees.
If you recall, in the pre-workshop, you created a GitHub account and associated it with your GitHub handle (or ID). You also configured your computer with a token (PAT) in a way that should seamlessly allow us to to create a remote repository on GitHub that will be linked to our local repository. Then we will share the changes we’ve made to our current project with the world.
3.1 Creating a Remote Repository
Log in to GitHub. Your personal dashboard is the first page you’ll see when you sign in on GitHub.
Tip: To access your personal dashboard once you’re signed in, click the invertocat
 logo in the upper-left corner of any page on GitHub.
logo in the upper-left corner of any page on GitHub.Click on the
+icon in the top right corner of your personal dashboard, thenNew RepositoryName your repository “planets”. Further down the page are other options available to us that can be toggled to suit the repository’s purpose. For this workshop it’s fine to create a “Public” repository. However, as this repository will be connected to a local repository, it needs to be empty. Therefore, leave “Add a README file” unchecked, and select “None” as options for both “Add .gitignore” and “Add a license.”
Creating Empty Repositories
More often than not, you will want to include a README, a .gitignore, and a license. We will talk more about these pieces in Part 4: bcgov GitHub Organization. However, because we are connecting to a locally created git repository that already contains documents, we need to provide a blank repository to connect with.
For most projects, I strongly recommend starting with a remote repository first (with a README, .gitignore and license automatically included), and then cloning this remote repository into a local location. We will go over cloning a repository in Section 3.5: Pulling changes from GitHub!
- Click “Create Repository”. As soon as the repository is created, GitHub displays a page with a URL and some information on how to configure your local repository.

- Make sure HTTPS is selected and then click the clipboard icon to copy the URL. We will use this URL in the next section.
You have effectively done the following on GitHub’s servers:
HTTPS vs SSH - what’s the difference?
HTTP and SSH refer to different protocols Git can use to transfer data. SSH is ubiquitous; many network admins have experience with them and many OS distributions are set up with them or have tools to manage them. Access over SSH is secure as all data transfer is encrypted and authenticated. It is also efficient, making the data as compact as possible before transferring it.
HTTP operates very similarly to the SSH protocol but runs over standard HTTPS ports and can use various HTTP authentication mechanisms, meaning it’s often easier on the user than something like SSH, since you can use things like username/password authentication rather than having to set up SSH keys.
If you remember back to the earlier episode where we added and committed our earlier work on mars.txt, we had a diagram of the local repository which looked like this:
![]()
Now that we have two repositories, we need a diagram like this

Note
Our local repository still contains our earlier work on mars.txt, but the remote repository on GitHub appears empty as it doesn’t contain any files yet.
3.2 Connecting to a Remote Repository
Now we connect the two repositories. We do this by making the GitHub repository a remote for the local repository. Remote branches are configured using the git remote command.
Go into the local planets repository, and run this command (using the URL copied to our clipboard):
$ git remote add origin <paste copied URL here>alternatively,
$ git remote add origin https://github.com/<yourusername>/planets.git
Note
“origin” is a local name used to refer to the remote repository. It could be called anything, but “origin” is a convention that is often used by default in git and GitHub, so it’s helpful to stick with this unless there’s a reason not to.
We can check that the command has worked by running git remote -v:
$ git remote -vorigin https://github.com/<yourusername>/planets.git (fetch)
origin https://github.com/<youusername>/planets.git (push)3.3 Push Local Changes to a Remote Repository
Now that authentication is setup, we can return to the remote. The git push command is used to upload local repository content to a remote repository. This command is how you transfer commits from your local repository to the repository on GitHub.
$ git push -u origin mainEnumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 8 threads.
Compressing objects: 100% (11/11), done.
Writing objects: 100% (16/16), 1.45 KiB | 372.00 KiB/s, done.
Total 16 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), done.
To https://github.com/<youusername>/planets.git
* [new branch] main -> mainThe git push command takes three arguments: the name of the remote repository (origin), the branch name (main) that you wish to push changes from, and -u to specify that the local main branch should track the remote main branch. Used without the branch name (git push origin) will push changes from all local branches to the remote. We may also use git push without specifying any arguments if we’ve already configured the remote for the current branch with the -u optoin. Git push will push only changes on our current branch to the remote.
push vs push origin vs push origin main vs push -u origin main??
It can get confusing trying to keep track of whether or not extra options are needed when pushing changes to the remote repository. As a good rule of thumb:
- On the first push from a branch to the remote (origin), use the full call:
git push -u origin mainso that the remote repository knows that themainbranch from your local machine should track themainbranch from the remote GitHub repository.- This is called setting your remote repository to be the
upstreamrepository. - It is the source of truth, and all changes should flow downstream from the remote GitHub repository to every local repository.
- This is called setting your remote repository to be the
- For every push from the same branch after this,
git pushwill be sufficient.
Now our repositories look like:

3.4 Pulling changes from GitHub
Git allows you to work collaboratively, with multiple people making changes to the same repo and sharing those changes through GitHub. We’ve seen how to create a repository and push changes to it; now we will see how to pull another person’s changes from Github.
Start by opening a second terminal window. This window will represent your colleague, working on another computer. In the second window, navigate to the folder one level “up” in the directory tree from where you have your planets repository.
$ cd c:/users/bashcrof
$ lsplanetsYou don’t want to overwrite your first version of planets.git, so you will clone the planets repository to a different location.
$ mkdir collab
$ cd collabClone the planets repo substituting in your GitHub user name. You can also find the URL from GitHub. Open the remote repository on GitHub, click on the <> Code button, and then copy the URL from there.

git clone https://github.com/<your-GitHub-username>/planets.gitCloning into 'planets'...
remote: Enumerating objects: 10, done.
remote: Counting objects: 100% (10/10), done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 10 (delta 2), reused 10 (delta 2), pack-reused 0
Receiving objects: 100% (10/10), done.
Resolving deltas: 100% (2/2), done.
Remote Add Origin vs. Clone
Note that when we clone a remote GitHub repository instead of connecting a blank repository to a local repository, we didn’t have to create a remote called origin: Git uses this name by default when we clone a repository into a new local location. (This is why origin was a sensible choice earlier when we were setting up remotes by hand.)
You can check that the remote ‘origin’ repository has been properly set up using the git remote -v command again.
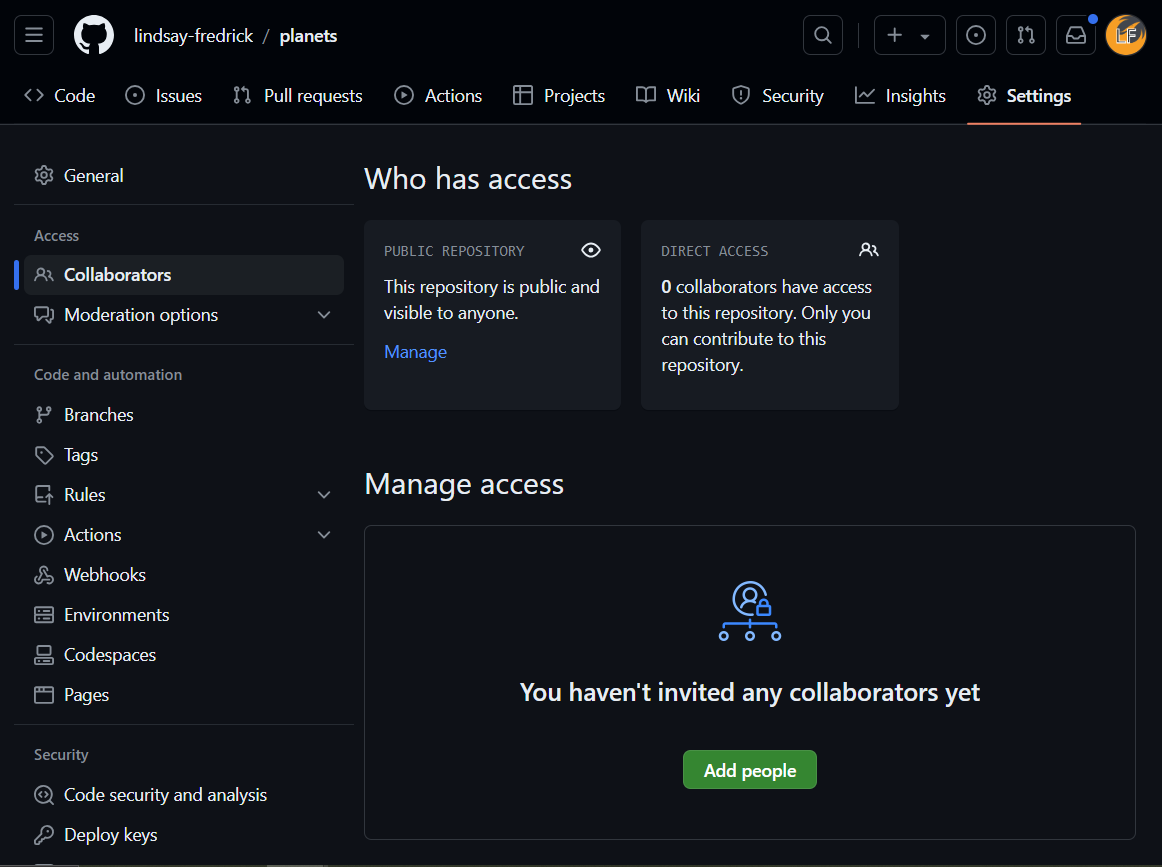
Giving Collaborators Access
In this scenario, you won’t need to give anyone access on GitHub, because GitHub will recognize both contributors as you.
However, typically you will need to allow access to other members of GitHub - otherwise anyone could go in and update your files at any point!
To give collaborator access, navigate to the repository page on GitHub, and click the “Settings” button on the right of the banner. Then, click “Add people” and then enter the username of the person you wish to collaborate with.
You should now have a new planets folder in the collab directory. Switch to this planets folder using the cd command. You can now make a change in your clone of the original repository, exactly the same way as we’ve been doing before. Add a line of text to a .txt file (using your favourite text editing software) and save it to your cloned repository.
$ cat pluto.txtIt is so a planet!Once we are happy with the changes we have made to the project, we can commit each change locally.
$ git add pluto.txt
$ git commit -m "Add notes about Pluto" 1 file changed, 1 insertion(+)
create mode 100644 pluto.txtAt this point, stop and compare the three repositories.
Original Repository
├── planets
| ├── mars.txt
| ├── .gitGitHub Repository
├── planets
| ├── mars.txt
| ├── .gitCloned Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitNotice how we only have the new pluto.txt file in the cloned repository. At this point, we have not yet told any of the other locations about the changes we have made. To communicate the changes and add them to our shared, source of truth, remote repository, we once again do a git push command. Note that because we cloned this repository from an already existing source, Git will already know that this main branch is set up to track the remote main branch, and so we do not need any further arguments:
$ git pushEnumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 12 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 302 bytes | 302.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To https://github.com/<yourusername>/planets.git
3abcea2..b792d59 main -> mainNow our three work locations will look something like this:
Original Repository
├── planets
| ├── mars.txt
| ├── .gitGitHub Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitCloned Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitWe have told (pushed) the remote repository that we have made changes, and sent them to the remote repo. However, the original repository is still unaware of the changes that have been made.
To download your changes from GitHub, switch back to the bash window (where you were working in your original repository) and enter:
$ git pull origin mainFrom https://github.com/<yourusername>/planets
* branch main -> FETCH_HEAD
Updating 3abcea2..b792d59
Fast-forward
pluto.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 pluto.txtThe git pull command also takes two arguments: the name of the remote repository (origin) and the remote branch name (main). The full command will pull any new changes present on the main branch of the remote repository into the local main branch (and then further merge these changes into your current branch). We may also use git pull without specifying any arguments if we’ve already configured the upstream remote for the current branch.
pull vs pull origin main??
Just like with pushes, it can be confusing to remember if we need further arguments when pulling from the remote repository. As a good rule of thumb:
- If we have cloned the repository, OR made sure that the remote branch is set up to be upstream from our own via a previous push,
git pullwill suffice.- This will pull any remote changes on the branch you are currently using into your local copy of the same branch.
- Note that this will not work if we have not yet set up a local branch to track an upstream remote branch.
- If we explicitly want to merge the
mainbranch of the remote repository into some other local branch of work,git pull origin mainwill be required.- Again, working off of multiple branches is a more complex method of work that we will not get into here. If you would like to learn more about branching in git, you can read the official documentation here.
After pulling all the changes from the remote repository back to the original, our three repositories should now look like this:
Original Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitGitHub Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitCloned Repository
├── planets
| ├── mars.txt
| ├── pluto.txt ***
| ├── .gitNow the three repositories (original local, second local, and the one on GitHub) are back in sync!
3.5 A Typical Workflow
To this point, we have learned a lot of different git commands and workflows involved in tracking all of our changes, keeping our repositories up-to-date, and collaborating across computers using GitHub. While there are multiple levels of nuance that go into each of these steps, let’s lay out a typical workflow.
Tip
The table below doubles as a handy cheatsheet; take a screenshot and save for future reference!
| Order | Action | Git Command |
|---|---|---|
| 1 (Once Only) | Create remote | (Done on GitHub) |
| 2 (Once Only) | Clone remote | git clone https://github.com/path/to/remote |
| 3 | Update local | git pull origin main |
| 4 | Make changes | (Done in editor) |
| 5 | Stage changes | git add numbers.txt |
| 6 | Commit changes | git commit -m "Add 100 to numbers.txt" |
| 7 | Update remote | git push origin main |
3.6 Ignoring Things
What if we have files that we do not want Git to track for us, like backup files created by our editor or intermediate files created during data analysis? This often is the case in BC Government data projects.
Let’s create a file called a.csv that contains some data about the Red Planet’s average temperature. Open a new csv using Excel and add two columns named ‘Time’ and ‘Temperature’. Add a few rows of data if you want and save it to the planets directory. Then check the output of git status.
$ git statusOn branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.csv
nothing added to commit but untracked files present (use "git add" to track)Putting data files under version control can be a waste of disk space and may put privacy at risk. As many BC Stats projects involve data with PI or other sensitive information, we generally follow a best practice of not pushing data to GitHub. We accomplish this by creating a file in the root directory of our project called a .gitignore.
.gitignore files are plain text files; you can open the file with your chosen text editor. Open up your favorite text editor and type the following line into the first line of the file:
*.csvThen save and close the file, naming it .gitignore. Don’t forget the dot at the beginning!
No .txt!
Although a .gitignore is a plain text file, it doesn’t carry the “.txt” extension. To be sure you aren’t saving a .gitignore.txt file, check the “Hidden Items” check box under Show/hide in your File Explorer Window.
These patterns tell Git to ignore any file whose name ends in .csv. If any of these files were already being tracked, Git would continue to track them. So be sure to create your .gitignore early in the process!
Once we have created this file, the output of git status is much cleaner:
$ git statusOn branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)On Unix-based operating system these files are called hidden files but on a PC they are not hidden. As Git Bash provides a Unix-like environments, to see your .gitignore in Git Bash, type “ls -a”.
And since everyone we are sharing our repository with will probably want to ignore the same things that we are ignoring, let’s add and commit our .gitignore:
$ git add .gitignore
$ git commit -m "Ignore data file"Now if we try to add our csv files, .gitignore helps us avoid accidentally adding files to the repository that we don’t want to track. It also gives us a way to override the .gitignore with the -f flag.
$ git add a.csvThe following paths are ignored by one of your .gitignore files:
a.csv
Use -f if you really want to add them.Go ahead and push your .gitignore to the remote so other people working on our project can use it too.
$ git pushWe can also ignore full subfolders by adding the folder name to our .gitignore.
Add another line to your .gitignore so it looks like:
*.csv
results/Make a subfolder in planets:
$ mkdir resultsAnd then add a .txt file to that subfolder. Again, open up your favorite text editor and add some text to a file and save your changes. Switch back to command line when you’re finished and check the git status.
$ git statusgit status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)The subfolder “results” and it’s contents are ignored. This is handy for keeping all of your data in a single folder. You simply add the data folder to your .gitignore and the contents will not be accidentally pushed.