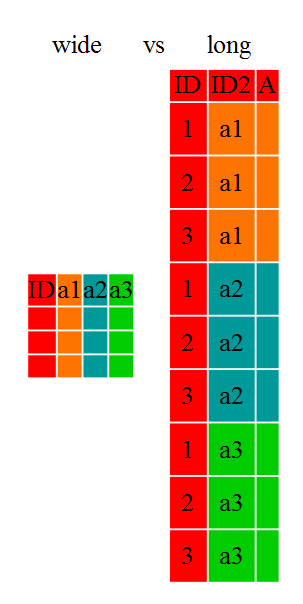
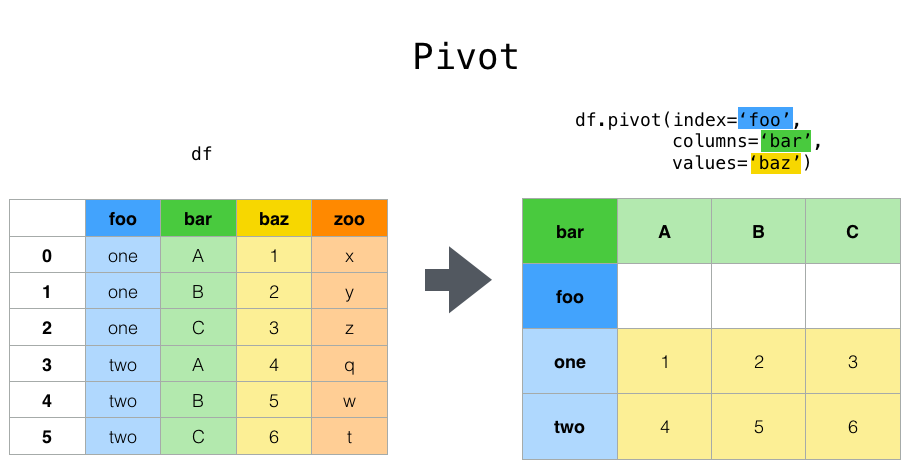
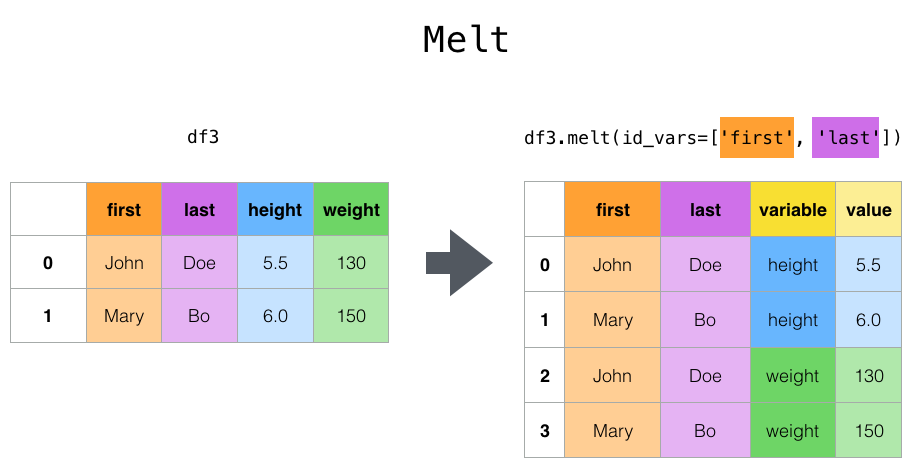
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:1944, in GroupBy._agg_py_fallback(self, how, values, ndim, alt)
1943 try:
-> 1944 res_values = self._grouper.agg_series(ser, alt, preserve_dtype=True)
1945 except Exception as err:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/ops.py:873, in BaseGrouper.agg_series(self, obj, func, preserve_dtype)
871 preserve_dtype = True
--> 873 result = self._aggregate_series_pure_python(obj, func)
875 npvalues = lib.maybe_convert_objects(result, try_float=False)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/ops.py:894, in BaseGrouper._aggregate_series_pure_python(self, obj, func)
893 for i, group in enumerate(splitter):
--> 894 res = func(group)
895 res = extract_result(res)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:2461, in GroupBy.mean.<locals>.<lambda>(x)
2458 else:
2459 result = self._cython_agg_general(
2460 "mean",
-> 2461 alt=lambda x: Series(x, copy=False).mean(numeric_only=numeric_only),
2462 numeric_only=numeric_only,
2463 )
2464 return result.__finalize__(self.obj, method="groupby")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/series.py:6570, in Series.mean(self, axis, skipna, numeric_only, **kwargs)
6562 @doc(make_doc("mean", ndim=1))
6563 def mean(
6564 self,
(...)
6568 **kwargs,
6569 ):
-> 6570 return NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/generic.py:12485, in NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
12478 def mean(
12479 self,
12480 axis: Axis | None = 0,
(...)
12483 **kwargs,
12484 ) -> Series | float:
> 12485 return self._stat_function(
12486 "mean", nanops.nanmean, axis, skipna, numeric_only, **kwargs
12487 )
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/generic.py:12442, in NDFrame._stat_function(self, name, func, axis, skipna, numeric_only, **kwargs)
12440 validate_bool_kwarg(skipna, "skipna", none_allowed=False)
> 12442 return self._reduce(
12443 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only
12444 )
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/series.py:6478, in Series._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
6474 raise TypeError(
6475 f"Series.{name} does not allow {kwd_name}={numeric_only} "
6476 "with non-numeric dtypes."
6477 )
-> 6478 return op(delegate, skipna=skipna, **kwds)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/nanops.py:147, in bottleneck_switch.__call__.<locals>.f(values, axis, skipna, **kwds)
146 else:
--> 147 result = alt(values, axis=axis, skipna=skipna, **kwds)
149 return result
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/nanops.py:404, in _datetimelike_compat.<locals>.new_func(values, axis, skipna, mask, **kwargs)
402 mask = isna(values)
--> 404 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
406 if datetimelike:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/nanops.py:720, in nanmean(values, axis, skipna, mask)
719 the_sum = values.sum(axis, dtype=dtype_sum)
--> 720 the_sum = _ensure_numeric(the_sum)
722 if axis is not None and getattr(the_sum, "ndim", False):
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/nanops.py:1701, in _ensure_numeric(x)
1699 if isinstance(x, str):
1700 # GH#44008, GH#36703 avoid casting e.g. strings to numeric
-> 1701 raise TypeError(f"Could not convert string '{x}' to numeric")
1702 try:
TypeError: Could not convert string 'AlgeriaAngolaBeninBotswanaBurkina FasoBurundiCameroonCentral African RepublicChadComorosCongo Dem. Rep.Congo Rep.Cote d'IvoireDjiboutiEgyptEquatorial GuineaEritreaEthiopiaGabonGambiaGhanaGuineaGuinea-BissauKenyaLesothoLiberiaLibyaMadagascarMalawiMaliMauritaniaMauritiusMoroccoMozambiqueNamibiaNigerNigeriaReunionRwandaSao Tome and PrincipeSenegalSierra LeoneSomaliaSouth AfricaSudanSwazilandTanzaniaTogoTunisiaUgandaZambiaZimbabwe' to numeric
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last)
Cell In[49], line 1
----> 1 gapminder_year_continent_country = gapminder.pivot_table(
2 index='year',
3 columns='continent',
4 values='country'
5 )
6 gapminder_year_continent_country.head()
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/frame.py:9536, in DataFrame.pivot_table(self, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
9519 @Substitution("")
9520 @Appender(_shared_docs["pivot_table"])
9521 def pivot_table(
(...)
9532 sort: bool = True,
9533 ) -> DataFrame:
9534 from pandas.core.reshape.pivot import pivot_table
-> 9536 return pivot_table(
9537 self,
9538 values=values,
9539 index=index,
9540 columns=columns,
9541 aggfunc=aggfunc,
9542 fill_value=fill_value,
9543 margins=margins,
9544 dropna=dropna,
9545 margins_name=margins_name,
9546 observed=observed,
9547 sort=sort,
9548 )
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/reshape/pivot.py:102, in pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
99 table = concat(pieces, keys=keys, axis=1)
100 return table.__finalize__(data, method="pivot_table")
--> 102 table = __internal_pivot_table(
103 data,
104 values,
105 index,
106 columns,
107 aggfunc,
108 fill_value,
109 margins,
110 dropna,
111 margins_name,
112 observed,
113 sort,
114 )
115 return table.__finalize__(data, method="pivot_table")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/reshape/pivot.py:183, in __internal_pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
173 if observed is lib.no_default and any(
174 ping._passed_categorical for ping in grouped._grouper.groupings
175 ):
176 warnings.warn(
177 "The default value of observed=False is deprecated and will change "
178 "to observed=True in a future version of pandas. Specify "
(...)
181 stacklevel=find_stack_level(),
182 )
--> 183 agged = grouped.agg(aggfunc)
185 if dropna and isinstance(agged, ABCDataFrame) and len(agged.columns):
186 agged = agged.dropna(how="all")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/generic.py:1432, in DataFrameGroupBy.aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
1429 kwargs["engine_kwargs"] = engine_kwargs
1431 op = GroupByApply(self, func, args=args, kwargs=kwargs)
-> 1432 result = op.agg()
1433 if not is_dict_like(func) and result is not None:
1434 # GH #52849
1435 if not self.as_index and is_list_like(func):
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/apply.py:187, in Apply.agg(self)
184 kwargs = self.kwargs
186 if isinstance(func, str):
--> 187 return self.apply_str()
189 if is_dict_like(func):
190 return self.agg_dict_like()
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/apply.py:603, in Apply.apply_str(self)
601 else:
602 self.kwargs["axis"] = self.axis
--> 603 return self._apply_str(obj, func, *self.args, **self.kwargs)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/apply.py:693, in Apply._apply_str(self, obj, func, *args, **kwargs)
691 f = getattr(obj, func)
692 if callable(f):
--> 693 return f(*args, **kwargs)
695 # people may aggregate on a non-callable attribute
696 # but don't let them think they can pass args to it
697 assert len(args) == 0
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:2459, in GroupBy.mean(self, numeric_only, engine, engine_kwargs)
2452 return self._numba_agg_general(
2453 grouped_mean,
2454 executor.float_dtype_mapping,
2455 engine_kwargs,
2456 min_periods=0,
2457 )
2458 else:
-> 2459 result = self._cython_agg_general(
2460 "mean",
2461 alt=lambda x: Series(x, copy=False).mean(numeric_only=numeric_only),
2462 numeric_only=numeric_only,
2463 )
2464 return result.__finalize__(self.obj, method="groupby")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:2005, in GroupBy._cython_agg_general(self, how, alt, numeric_only, min_count, **kwargs)
2002 result = self._agg_py_fallback(how, values, ndim=data.ndim, alt=alt)
2003 return result
-> 2005 new_mgr = data.grouped_reduce(array_func)
2006 res = self._wrap_agged_manager(new_mgr)
2007 if how in ["idxmin", "idxmax"]:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/internals/managers.py:1488, in BlockManager.grouped_reduce(self, func)
1484 if blk.is_object:
1485 # split on object-dtype blocks bc some columns may raise
1486 # while others do not.
1487 for sb in blk._split():
-> 1488 applied = sb.apply(func)
1489 result_blocks = extend_blocks(applied, result_blocks)
1490 else:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/internals/blocks.py:395, in Block.apply(self, func, **kwargs)
389 @final
390 def apply(self, func, **kwargs) -> list[Block]:
391 """
392 apply the function to my values; return a block if we are not
393 one
394 """
--> 395 result = func(self.values, **kwargs)
397 result = maybe_coerce_values(result)
398 return self._split_op_result(result)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:2002, in GroupBy._cython_agg_general.<locals>.array_func(values)
1999 return result
2001 assert alt is not None
-> 2002 result = self._agg_py_fallback(how, values, ndim=data.ndim, alt=alt)
2003 return result
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/groupby/groupby.py:1948, in GroupBy._agg_py_fallback(self, how, values, ndim, alt)
1946 msg = f"agg function failed [how->{how},dtype->{ser.dtype}]"
1947 # preserve the kind of exception that raised
-> 1948 raise type(err)(msg) from err
1950 dtype = ser.dtype
1951 if dtype == object:
TypeError: agg function failed [how->mean,dtype->object]