OCA Bundle Creation¶
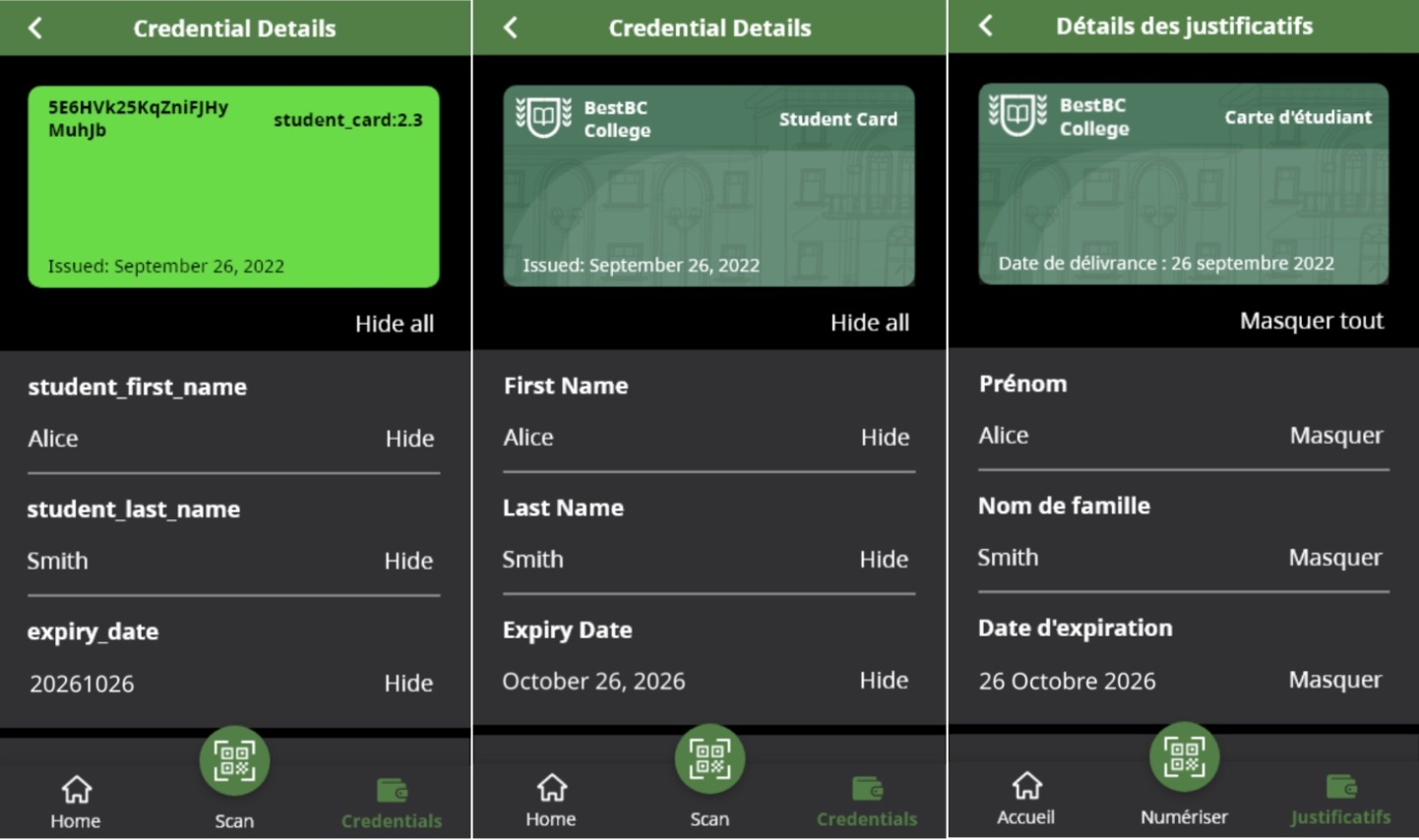
An OCA (Overlays Capture Architecture) Bundle allows verifiable credential issuers to customize the display of their credential, managing translations, branding, attribute rendering, etc. The image belows shows an example of a verifiable credential displayed without an OCA Bundle, and the same credential with an OCA Bundle, first in English and then in French. OCA Bundles are used by mobile wallets, such as those built on the OpenWallet Foundation's Bifold Wallet.
Creating an OCA Bundle from scratch consists of a two parts.
- Creating the information needed to create the OCA Bundle for submitting a GitHub Issue in the Aries OCA Bundles repository to have the OCA Bundle created. This is usually handled by an Issuer team member, often a designer, collaborating with translation experts. This part is covered in this document.
- The (quite technical) process of submitting a GitHub Pull Request (PR) to publish the OCA Bundle and make it available to Wallets. Since the process is quite technical, feel free to stop at the "Create Issue" part, and we (the maintainers of the Aries OCA Bundles repo) will take it from there -- getting an approval from the Issuer team along the way. The instructions for the second part are in the Create the OCA Bundle PR document.
So, to get as far as creating a GitHub Issue, here's a summary of what you are going to do:
- Create the OCA Bundle source data using Excel, the OCA Explorer site and a text editor, including identifying the logo, images and other branding data.
- Gather the identifiers (schemaId or credDefId) for the credential to which the bundle applies.
- Define where in the Aries OCA Bundles repository the OCA Bundle should be placed.
- Create a GitHub Issue in the Aries OCA Bundles repository, attaching the files and information about the new OCA Bundle.
We'll cover each steps in the following sections.
Collect the OCA Bundle Source Data¶
To get started, you (the Issuer) will need to collect some basic information about the credential for which you are building an OCA Bundle. If you are not familiar with how you can control the display of a credential using an OCA Bundle, please take a look at the result of applying OCA Bundles to existing credentials, by going to the OCA Explorer tab of this website. There, you can select and review the existing credentials, and see how others have used OCA for their credentials. You should also review the OCA for Aries Style Guide. It has the details about what you can control in displaying your credential, and Do's and Don'ts as you create your bundle.
Once you have an idea of what you are going to be doing, you need to gather some data:
- The list of attributes and their data types in the credential. That will usually come from the technical team creating the credential issuer software. The attribute names must match exactly what is in the schema for the credential type.
- The images that you want to use in displaying your credential -- a logo, background image and a background image slice. Guidelines for, and how the images will be used, are below.
- The colours (or colors) you want to use for the credential -- a primary and secondary, in RGB hex format.
You will (later) use the OCA Explorer to experiment with your images and colours as you adjust them to be just right.
Note
In most cases, you only create one OCA Bundle for a credential that your organization Issues, and use it for the Dev, Test and Production sites. Often, a watermark is added to differentiate a "Test" credential from a production one -- the addition of the watermark is covered in the later creating the PR part of the process. However, you want to have different OCA Bundles for Dev/Test and Production beyond the just the watermark difference. If you do, please create multiple OCA Bundles, identifying the target environment for each. It adds management overhead, but that's all. It's up to you.
Create the OCA Excel File¶
Next up is to populate an Excel spreadsheet with the core and language-specific information about your credential type. Start by downloading this OCA Excel File that you will save locally and then populate with details about your credential. You can name the local file whatever you want. Open up the file in Excel and use the instructions in the file to populate the document for your credential. Here is a quick summary of the process, thoroughly documented in the Excel file (Documentation tab):
- On the "Main" tab, enter a list of the attributes, their data types, and a flag indicating if an attribute is Personally Identifiable Information (PII).
- On the language tabs ("en" and "fr"), add in language-specific data about the Credential (name, description, Issuer, etc.), and a label and description about each pre-populated credential attribute. Other languages can be added/removed.
That's it. Save the Excel file and you are good to go. Right now, we don't have a good way to test the Excel file before it goes into the Aries OCA Bundles repository. We hope to add that soon.
If you want to update the Excel file after it has been put (merged) into the Aries OCA Bundles repository, make sure you download the latest version of the file from the repository before editing, so you don't lose any edits others may have made. Your local copy may not be the latest!
Generate The Branding JSON File¶
The second file you need to create is the branding.json file. The easiest way to create the file is to use the OCA Explorer. Unfortunately, doing that is a bit of a hack, but bear with us. We hope to have a smoother process soon.
The first step is to get the colors, logo, and images right. To do that, we'll use another credential's OCA Bundle, ignoring the attribute names and focusing on the appearance.
To do that:
- Loop:
- Create/retrieve/update the logo and other images to be used in the OCA Bundle.
- Make sure in creating/adjusting the images that you use the size guidelines in the OCA for Aries Style Guide RFC. We don't want massive image files -- they need to be as small (in bytes) as possible. In summary:
- Logo: 1:1 aspect ratio, 240x240px
- Background Image Slice: 1:10 aspect ratio, 120x1200px
- Background Image: 3:1 aspect ratio, 360x1080px
- Make sure in creating/adjusting the images that you use the size guidelines in the OCA for Aries Style Guide RFC. We don't want massive image files -- they need to be as small (in bytes) as possible. In summary:
- Go to the OCA Explorer Tab, and load any existing OCA Bundle.
- Ignore the attribute names (since they don't match your credential...) -- focus on the colors and images.
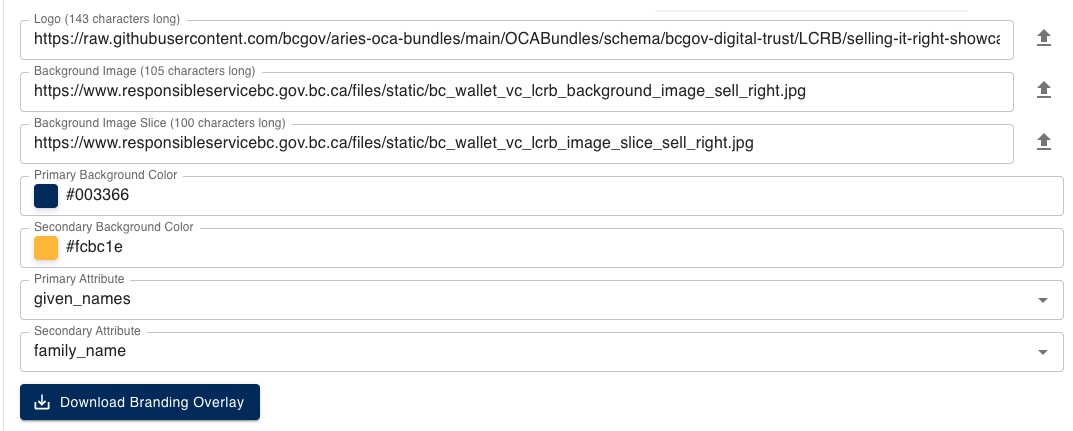
- Use the form at the bottom of the page (image below) and:
- Load the your images.
- You can either use URLs for the images or upload them into the form.
- You might upload them while you are iterating, and then use URLs when you are finished.
- Use the color picker to select the primary/secondary background colors appropriate for your Issuer.
- Ignore (for now) the primary/secondary attributes.
- Load the your images.
- Create/retrieve/update the logo and other images to be used in the OCA Bundle.
- Repeat until you have the logo, images and colors Just Right.
- Download the Branding JSON file (
branding.json) using the button at the bottom of the screen.
The OCA Explorer Branding form:
Here's what the file will look like. Two things to note:
- If you uploaded the images in the OCA Explorer and left them as is, those fields will be VERY long. That's a valid approach to handling the images, or you can change them as noted below.
- If you an attribute in the credential that holds the "Issued Date", and/or the "Expiry Date", type in the names of those attributes as value of the respective data elements (
"issued_date_attribute","expiry_date_attribute") below.
{
"capture_base": "",
"type": "aries/overlays/branding/1.0",
"digest": "",
"logo": "https://raw.githubusercontent.com/bcgov/aries-oca-bundles/main/OCABundles/schema/bcgov-digital-trust/LCRB/selling-it-right-showcase/bc-logo.jpg",
"background_image_slice": "https://www.responsibleservicebc.gov.bc.ca/files/static/bc_wallet_vc_lcrb_image_slice_sell_right.jpg",
"background_image": "https://www.responsibleservicebc.gov.bc.ca/files/static/bc_wallet_vc_lcrb_background_image_sell_right.jpg",
"primary_background_color": "#003366",
"secondary_background_color": "#fcbc1e",
"primary_attribute": "given_names",
"secondary_attribute": "family_name",
"issued_date_attribute": "",
"expiry_date_attribute": ""
}
To finalize the branding.json file:
- Load the downloaded file into a text editor, and:
- If needed, update the values for the images:
- If you intended to upload the images into the Aries OCA Bundles repository, set the image attribute values to just the file name without a path (e.g., "IssuerLogo.png").
- If you intend to use a remote URL for the images, enter the URL.
- Enter the primary and secondary credential attribute names specific to your credential.
- If applicable, enter the "issued_date_attribute" and/or "expiry_date_attribute" names.
- If needed, update the values for the images:
- Save the
branding.jsonfile.
Submit Your OCA Bundle As An Issue¶
We are now ready to create the first iteration of the OCA Bundle. Please create an Issue in the GitHub Aries OCA Bundles repository using the instructions below, and we (the Maintainers of the Aries OCA Bundles repo) will take it from there. We're happy to do that, and you will be able to approve the PR before it is merged into the repository. Once the PR is created and merged, we're happy for you to requests tweaks to the OCA Bundle via issues or PRs -- submitting updates to the Excel file, branding file or other information about the OCA Bundle.
Here's how to create the Issue.
- Click here to create a new GitHub Issue in the right repo.
- Call the issue "New OCA Bundle for Credential
<NAME>from Issuer<Issuer>" - In the description, include:
- A brief background of the request -- the project, and desired timeline for the OCA Bundle to be available in the Wallet.
- Propose where the OCA Bundle should go in the existing data structure. Likely that will be determined by the Issuer organization name, and the credential type. For example, "Within the BC Gov folder, in an LSBC folder and called "Lawyer".
- A list of names and email addresses of those that will be authorized to make/approve updates to the Bundle. Include your name and email, please.
- Attach at least the OCA Excel file and branding.json files.
- Attach the images that you want put into the OCA Bundle folder. If the images are embedded in the
branding.jsonfile, or are URLs to remote image files, the images need not be attached.
- If you know the following information, enter it in the description. Alternatively, you might ask a technical resource on your team that has this information to enter it into a comment on the Issue.
- The
credDefIds (and/orschemaIDs) associated with the OCA Bundle. For each:- Include the location of the ID (e.g. "CANdy Dev", "CANdy Test", etc.).
- Include the text of a "watermark", if any, for each Identifier, and in each desired language (e.g., English, French, etc.). For example: "TEST".
- The
That's it. We'll take it from there, using the Issue comments (or, email or, gasp the phone) to get any more details/clarifications we might need. We'll be back to you within a business day of submitting the issue with a progress report and/or questions -- ideally to say "all done". Our team will use your materials to create a PR. We’ll tag you in the PR for review, and once approved, we’ll merge the changes. The OCA Bundle will then become available in your wallet. After that, Issues or PRs (or emails) can be used to adjust the OCA Bundle as necessary based on testing with a Wallet.